Workflows
Workflows let you chain multiple AI tasks into a single pipeline. Each workflow is a directed acyclic graph (DAG) — a set of nodes connected by edges that define the execution order. Outputs from one node can feed into the next, letting you build complex multi-step processes like “enhance a prompt, generate an image from it, then animate the image into a video.”
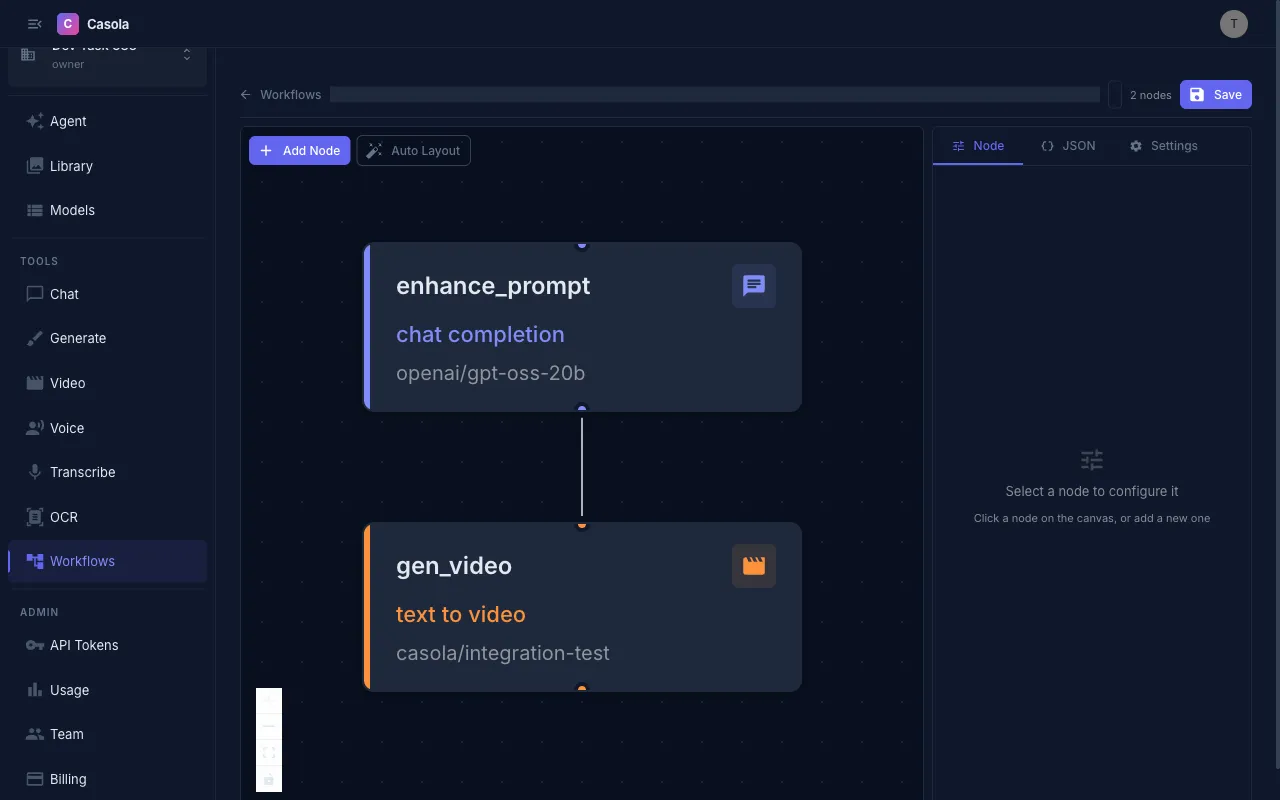
Creating a workflow
Section titled “Creating a workflow”Open Workflows from the sidebar and click New Workflow. You’ll be offered a set of templates or a blank canvas.
Templates
Section titled “Templates”Templates give you a pre-built workflow to start from:
- Prompt to Video — An LLM enhances your prompt, then a video model generates a clip from it. Great for turning rough ideas into polished video prompts.
- Parallel Image Gen — Three image generation nodes run simultaneously with the same input, giving you multiple variations to choose from.
Pick a template to start with a working pipeline, or choose Blank to build from scratch.
The workflow editor
Section titled “The workflow editor”The editor has a visual canvas on the left and a configuration panel on the right with three tabs:
Node tab
Section titled “Node tab”Select a node on the canvas to configure it:
- Task type — What kind of AI task this node performs (e.g. chat completion, image generation, text-to-video). See the Task Types reference for the full list.
- Model — Which model to use for this task. The dropdown shows models compatible with the selected task type.
- Payload fields — Task-specific inputs like prompt text, voice selection, or image URLs. Fields change based on the task type.
JSON tab
Section titled “JSON tab”View and edit the raw DAG definition as JSON. Useful for copying workflows between environments or making bulk edits.
Settings tab
Section titled “Settings tab”Configure workflow-level settings:
- Name — A label for this workflow
- Description — Optional notes about what the workflow does
- Region — Where to run jobs (Global, US, or EU). Defaults to Global.
- Timeout — Maximum execution time in seconds. Jobs that exceed this are cancelled.
- Input parameters — Named parameters that can be passed in when running the workflow (see Variables below)
Adding and connecting nodes
Section titled “Adding and connecting nodes”- Add a node — Click the add button on the canvas to create a new node, then configure its task type and model.
- Connect nodes — Drag from one node to another to create an edge. Edges define execution order — a node only runs after all its upstream nodes complete.
- Parallel execution — Nodes without edges between them run in parallel. In the “Parallel Image Gen” template, all three image nodes start at the same time.
The editor validates your graph automatically. It will warn you if:
- The graph contains a cycle (not allowed — must be acyclic)
- An edge references a node that doesn’t exist
- A node is missing a model selection
Variables
Section titled “Variables”Variables let you pass data between nodes and inject external input into a workflow.
Input parameters
Section titled “Input parameters”Define input parameters in the Settings tab. These are values that are provided each time the workflow runs. Reference them in node payloads with:
${input.prompt}${input.image_url}For example, a “Prompt to Video” workflow might define a prompt input parameter, then use ${input.prompt} in the first node’s payload.
Node output references
Section titled “Node output references”Reference the output of an upstream node using:
${nodes.<node_id>.result.<output_path>}The output path depends on the task type. Common examples:
| Task type | Output reference | What it returns |
|---|---|---|
openai/chat-completion | ${nodes.my_node.result.choices[0].message.content} | Generated text |
fal/text-to-image | ${nodes.my_node.result.images[0].url} | Image URL |
fal/text-to-video | ${nodes.my_node.result.video.url} | Video URL |
openai/audio-speech | ${nodes.my_node.result.audio_url} | Audio URL |
openai/audio-transcription | ${nodes.my_node.result.text} | Transcription text |
The editor shows reference chips below input fields — click a chip to insert the reference into the field you’re editing.
Running a workflow
Section titled “Running a workflow”Click Run in the editor toolbar. If the workflow has input parameters, you’ll be prompted to provide values for each one. The workflow then submits as an async job.
Execution history
Section titled “Execution history”Each workflow run appears in the execution history. Click a run to see:
- Status — Running, completed, failed, cancelled, or timed out
- Node results — The output of each node in the pipeline
- Timing — When each node started and finished
- Errors — If a node failed, the error details
Map nodes (fan-out)
Section titled “Map nodes (fan-out)”Map nodes let you run the same task once for each item in an array — fan-out. Instead of manually creating N parallel nodes, you define a single map node and the engine spawns one sub-job per array element.
A map node has four key properties:
| Property | Description |
|---|---|
items | Template expression that resolves to an array at runtime (e.g. ${input.prompts} or ${nodes.splitter.result.chunks}) |
node | The inner task to run for each item — same shape as a regular task node (model_id, task, payload) |
tolerance | Fraction of sub-jobs allowed to fail (0–1). 0 = strict (any failure fails the map node), 1 = tolerate all failures |
max_concurrency | Optional limit on how many sub-jobs run in parallel |
$each and ${item.X} interpolation
Section titled “$each and ${item.X} interpolation”Inside a map node’s inner payload, use $each to expand an array into repeated template values, and ${item.X} to reference the current array element.
${item.X} — When the engine fans out a map node, each sub-job receives one element from the items array as item. If your items are objects, use dot notation to access fields:
{ "prompt": "${item.text}", "negative_prompt": "${item.negative}"}If items are plain strings, use ${item} directly (no dot path).
$each — Use $each blocks in any payload (not just map nodes) to expand an array into repeated values inline. An $each object has two fields:
$each— a template expression resolving to an arraytemplate— the shape to stamp out for each element
{ "messages": [ {"role": "system", "content": "You are a helpful assistant."}, { "$each": "${input.messages}", "template": { "role": "${item.role}", "content": "${item.content}" } } ]}This expands the $each block into one message object per element in input.messages.
casola/pick (built-in task)
Section titled “casola/pick (built-in task)”casola/pick is a built-in task that extracts elements from an array by index — no GPU dispatch needed. Use it after a map node to select specific results.
Payload fields:
| Field | Type | Description |
|---|---|---|
source | array or template | The array to pick from (e.g. ${nodes.generate.result.items}) |
indices | number[] | Zero-based indices to extract |
The result is { items: [...] } containing only the selected elements.
Example: Batch image generation with selection
Section titled “Example: Batch image generation with selection”This workflow takes a list of prompts, generates an image for each one using a map node, then picks the first and third results:
{ "nodes": { "generate": { "type": "map", "items": "${input.prompts}", "node": { "model_id": "black-forest-labs/FLUX.1-schnell", "task": "fal/text-to-image", "payload": { "prompt": "${item}" } }, "tolerance": 0 }, "select": { "type": "task", "model_id": "casola/pick", "task": "casola/pick", "payload": { "source": "${nodes.generate.result.items}", "indices": [0, 2] } } }, "edges": [ {"from": "generate", "to": "select"} ]}When executed with input_params: { "prompts": ["a cat in space", "a dog on the moon", "a bird underwater"] }, the generate map node creates three image generation sub-jobs in parallel. Once all complete, select picks the first and third images.
Tolerance
Section titled “Tolerance”The tolerance field on a map node controls how partial failures are handled:
0(default) — Strict mode. If any sub-job fails, the entire map node fails and the workflow stops.0.5— Up to 50% of sub-jobs can fail. The map node still succeeds with partial results.1— All sub-jobs can fail. The map node always succeeds (result may be empty).
Failed sub-jobs produce null entries in the result array, preserving the original ordering.
Available task types
Section titled “Available task types”Workflows support all task types on the platform, organized by category:
| Category | Task types |
|---|---|
| Text | Chat completion, embeddings |
| Image | Image generation, text-to-image, image editing |
| Video | Text-to-video, image-to-video, speech-to-video, video interpolation |
| Audio | Text-to-speech, audio transcription |
Each task type has specific input fields and output formats. See the Task Types reference for full details on every task type, including input fields and output schemas.
API usage
Section titled “API usage”Create a workflow
Section titled “Create a workflow”curl -X POST https://api.casola.ai/api/workflows \ -H "Authorization: Bearer YOUR_API_TOKEN" \ -H "Content-Type: application/json" \ -d '{ "name": "Prompt to Video", "description": "Enhance a prompt with an LLM, then generate a video from it", "dag": { "nodes": { "enhance": { "model_id": "Qwen/Qwen3.5-4B", "task": "openai/chat-completion", "inputs": { "messages": [ { "role": "system", "content": "Rewrite the following prompt to be more detailed and cinematic for video generation." }, { "role": "user", "content": "${input.prompt}" } ] }, "outputs": ["choices[0].message.content"] }, "generate_video": { "model_id": "fal-ai/wan/v2.2-5b", "task": "fal/text-to-video", "inputs": { "prompt": "${nodes.enhance.result.choices[0].message.content}", "num_frames": 81, "fps": 16 }, "outputs": ["video.url"] } }, "edges": [ {"from": "enhance", "to": "generate_video"} ] } }'Response (201):
{ "workflow": { "id": "wf_abc123", "organization_id": "org_xyz", "name": "Prompt to Video", "dag": { "..." : "..." }, "created_at": 1711234567, "updated_at": 1711234567 }, "diagnostics": { "type_issues": [], "warnings": [] }}Execute a workflow
Section titled “Execute a workflow”curl -X POST https://api.casola.ai/api/workflows/wf_abc123/execute \ -H "Authorization: Bearer YOUR_API_TOKEN" \ -H "Content-Type: application/json" \ -d '{ "input_params": { "prompt": "a cat playing piano in a jazz bar" } }'Response:
{ "execution": { "id": "exec_def456", "workflow_id": "wf_abc123", "organization_id": "org_xyz", "status": "pending", "input_params": {"prompt": "a cat playing piano in a jazz bar"}, "outputs": null, "error": null, "created_at": 1711234567, "updated_at": 1711234567 }}Poll execution status
Section titled “Poll execution status”curl https://api.casola.ai/api/workflow-executions/exec_def456 \ -H "Authorization: Bearer YOUR_API_TOKEN"When all nodes complete, the response includes outputs from each node. The workflow status transitions through pending → running → completed (or failed).